Data science & IA
Défense : «Le recrutement dans le secteur de l'IA est un enjeu stratégique» (Libération)
09.03.2024

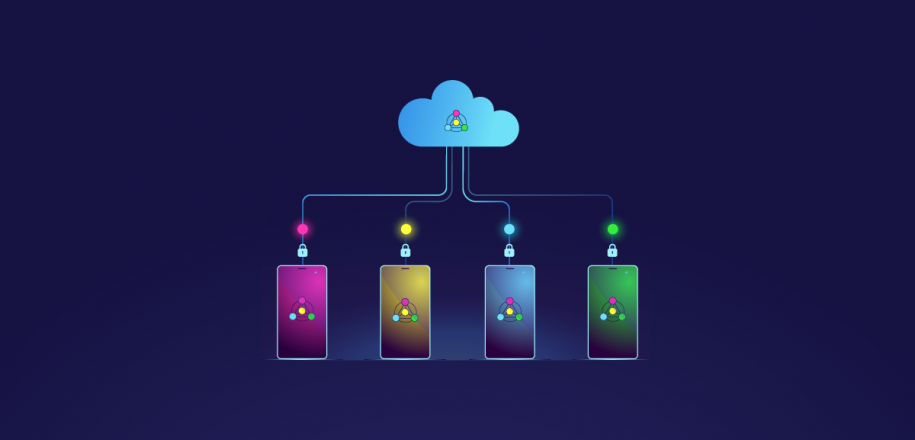
It means that you have at your disposal a massive amount of data stored in different places. And you want the computer to extract the most valuable information from them. The specificity of Federated learning is to have one main server (the central intelligence) that communicates with all the servers holding the data. And, in order to be privacy-friendly, all the data must remain on its device, on its server.
So, Federated learning has been designed to work within the following settings:
Let’s take the example of a smart keyboard.
This keyboard would be able to remember what you typed and would suggest the following words to improve the user experience. By extrapolating, it might even suggest you to visit one place or buy something…
To make this possible, there has to be an intelligence, an algorithm somewhere, that analyzes your data.
Of course, you want to keep your data private without the company reading and monitoring what you write while enjoying personalized services. These two desires seem at first sight incompatible.
The solution found by Google is Federated learning. Data never leaves your devices but is analyzed locally. It leads to training a local model adapted to your needs. Then this local model is broadcast to a central server that gathers models from all the devices of the network and computes a global model. This global model is more general and is sent back to all nodes. From this global model, you enhance the model you own. And you keep iterating these few steps to attain the best achievable model.
Federated Learning is very powerful because unlike classical AI approaches, it does not need to gather all data in one place. It follows that it respects privacy and allows to train a more accurate model quicker.
However, it has been recently found that it is still possible to deduce your personal information. It is hard, much harder, but yet possible. Data can be recovered from the exchange of models between servers.
Data privacy is a burning issue that must be solved ! This concern is at the core of the Federated Learning paradigm.
To fix this glitch, one common approach is to introduce a blur, an error into the data. But due to this artificially added error, the accuracy of the model may decrease. These issues lead to a constellation of questions. How can we ensure a total privacy ? At which cost ? How can we ensure the model to be accurate enough ? How can we speed-up training ? How can we conciliate highly heterogeneous data ?
These questions are open and are presently being studied by the AI community.
__________________________________________________
__________________________________________________
Illustration: Designed by fullvector / Freepik